タイピングゲーム「寿司打」を Python によるGUIオートメーションで光学文字認識(OCR)で自動化してみたら上手く動いたので、システム構成とか工夫した点について簡単にまとめます。
作成した自動化のソースコードを公開すると荒らしが増えそうなので自粛していますが、 「こういうものを作ってみたい」「考えていたことを先に実現された」「メンターとして教えてくれ」 などの声は届いているので、これを読んで参考になれば幸いです。
タイピングゲーム「寿司打」をPyAutoGUI + 画像認識 (OCR)で自動化した結果 pic.twitter.com/p9EgvlpvpN
— まこ (@tex2e) February 10, 2019
ちなみに、合計で340枚以上とるとゲーム側でエラーが発生してしまうので、わざと途中で終了するようにしています。 本当ならもっと高いスコアを出せたはずなのですが…
作成したシステムの構成技術は以下の通りです。もちろんPython使ってます。
- PyAutoGUI: オートメーションによるキーボードとマウスの制御(ゲーム操作、タイピング)
- PyAutoGUI: 画像認識(ゲーム開始時に画面がどこにあるかを検知するため)
- Tesseract + PyOCR: 光学文字認識(表示されたローマ字を読み取るため)
以下ではPyAutoGUIを知っている前提で、画像認識と光学文字認識について説明します。
画像認識
RPAでは画面上のウィンドウの位置がずれると正しく処理できなくなる問題が往々にして起こります。 PyAutoGUIでクリックする座標をハードコードするのは同様の問題が発生しそうなので、 ここでは pyautogui.locateCenterOnScreen(imgfile) 関数を使います。 これは、クリックしたい場所の画像を渡すと画面上から探して、その中心座標を返してくれる関数です。 これによってゲームを起動しているブラウザのウィンドウが、 画面上のどこにあってもスタートすることができます。
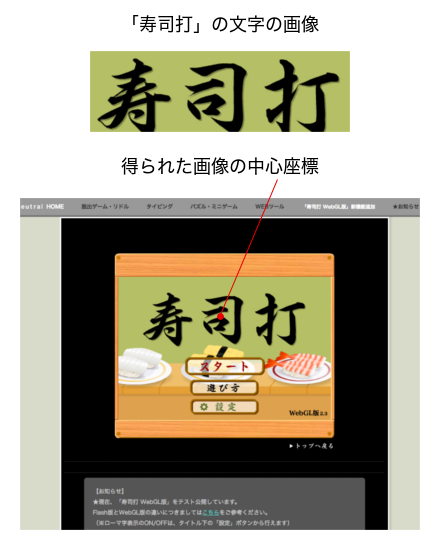
今回の場合はゲーム画面のサイズは固定なので、 スタートボタンなどは求めた座標からの相対位置でクリックする場所を指定してあげればいいです。
光学文字認識
文字認識をするためには画面のスクリーンショットを撮る必要がありますが、 PyAutoGUI には pyautogui.screenshot() という関数があるので簡単にできます。 また、画面全体のスクリーンショットを撮るには時間がかかるので、 引数に region=(左, 上, 幅, 高さ) と指定して特定の範囲だけ撮るといいと思います。
文字認識をするに当たっては Tesseract を使い、 そのPythonバインディングは PyOCR を使いました。 文字認識は入力する画像が大きくなるほど処理時間が長くなります。 そこで、文字が存在する最低限の大きさに画像を切り取る(抽出する)ことで、 処理速度を高速化することができます。
何度か実験してみたところ、文字認識は「背景が白で文字が黒」の方が識字率が高くなる傾向があるので、 実際にはグレースケールにして2値化した画像の色を反転させるという画像処理をしています。

上図を見てもらうと、 わかりにくいですが2値化によって背景にある皿や湯呑みのイラストが消えていることが確認できます。 これによって背景の余計な部分が消えて文字認識の精度が向上します。
Pythonでの画像処理や光学文字認識のやり方についてはここでは説明しませんが、 文字認識ができれば文字列(今回はローマ字)が得られるので、 あとは pyautogui.typewrite(chars) で自動でタイピングすれば完成です。 なお、誤った文字認識でタイピングした結果、皿が取れないこともあります。 ですが、入力済みの文字はグレーアウトしていて、 画像処理の2値化によって入力画像から入力済みの文字を消すことができるので、 再度画像認識することによってタイピングを続けることができます(もちろんミスタイプは増えますが)。
前述したように340枚以上とるとゲームがエラーで終了するので、 繰り返し回数は340回として実行すれば以下の動画のようになります。
実際にやっているときの様子です pic.twitter.com/FTTlBLvOY0
— まこ (@tex2e) February 10, 2019
タイピングというよりもはや、入力し終わる前に私たちが表示された文字を読み取れるか、 というゲームに化していますが、ずっと見ていても飽きませんね(本来なら5分ほどあります)。
終わりに
結局のところ、プログラムを書いた時間よりも、光学文字認識の精度を上げるために割いた時間の方が長くなりました。 RPAでは、画像認識や光学文字認識の精度を上げれば、かなり夢のある仕事ができるとは思います。 精度を考慮しなければ業務内容の高速化は簡単に成し遂げられます。
RPAは日本でも本格的に導入する機運が高まりつつあり、ワークスタイル変革やテレワークに続く「働き方改革」という意味でも使われることが多くなっています1。 RPAは構造化データの取得・入力・正誤チェックなどの入出力が定型的でルールが明確な業務での利用が主ですが、機械学習によって画像や音声のような非構造化データを学習し、RPAが得意な定型的なデータに加工することで、より広範囲な業務を自動化できるようになるでしょう2。
RPAがどのような組織・業務に導入されていくかを引き続き注目していくと共に、これからの機械学習分野の発展に期待したいです。
参考文献
- O'Reilly Japan - 退屈なことはPythonにやらせよう
- Programming a Bot to Play the "Sushi Go Round" Flash Game
- pyautogui – A cross-platform GUI automation Python module for human beings. Used to programmatically control the mouse & keyboard (GitHub)
- tesseract – Tesseract Open Source OCR Engine (GitHub)
- pyocr – A Python wrapper for Tesseract and Cuneiform (Gnome's Gitlab)